こんにちは、AWS担当のwakです。
前回・前々回の記事ではLambdaからSlackへの通知を行いましたが、そこではスクリプト内部にパラメーターをハードコードしていました。これを改善するためにDynamoDBを使おうと思ってコードのサンプルを探してみたのですが、古い記事や新しい記事が入り交じっていて何が最新なのかよく分からなくなってきたためまとめることにします。
この記事の内容
AWS Lambda(Node.js)からSDKを使ってDynamoDBを利用する際、クライアントオブジェクトを生成するためのやり方がいくつかあります。その内容について説明しています。
前提条件
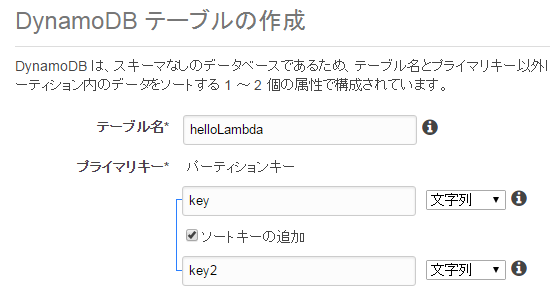
以下のコードは全てDynamoDBにアクセスする権限のあるロールでLambdaから実行しています。また、DynamoDBには事前にテーブルを作成し、数レコードのデータを投入してあるものとします。
DocumentClientを使う
もともとDnyamoDBをJavaScriptから利用するためのSDKとしてはAWS.DynamoDBというクラスがあるのですが(後述)、検索時に値の型を明示する必要があったりしてあまり使いやすいとは言えません。たとえば検索時や新規レコード挿入時に"ABC"という文字列を与えるのにもいちいち{"S" : "ABC"}というハッシュ(Sは文字列を意味するラベル)として渡す必要がありますし、逆に検索結果に"ABC"という文字列が含まれていても、結果は{"S" : "ABC"}というハッシュで返ってきます。
AWS.DynamoDB.DocumentClientはこの辺りを改善し、より簡単にAPIを利用するためにSDKを呼び出すラッパーライブラリです。2015年10月にバージョン2.2.0がリリースされました。
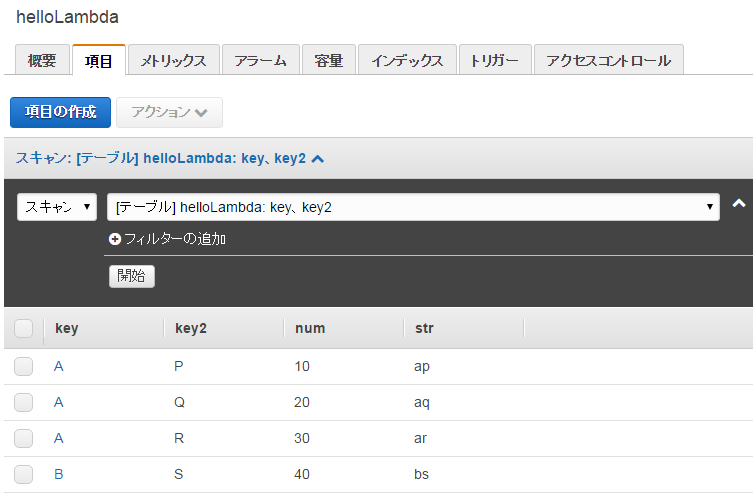
次のコードはscan()メソッドを使い、指定したテーブルにある全レコード*1を取得してログへ出力します。
var AWS = require("aws-sdk");
var dynamo = new AWS.DynamoDB.DocumentClient();
exports.handler = function(event, context) {
dynamo.scan({TableName : "TABLENAME"}, function(err, data) {
if (err) {
context.fail(err);
} else {
context.succeed(data);
}
});
};
条件を指定して検索を行うには何通りかの方法があります。
scan()で検索
scan()に渡すパラメーターに条件を追加してあげれば検索ができます。たとえばSQLで SELECT * FROM TABLENAME WHERE num = 10 に相当する検索を行いたければこうなります。
var param = {
TableName : "TABLENAME",
FilterExpression : "num = :val",
ExpressionAttributeValues : {":val" : 10}
};
dynamo.scan(param, function(err, data) { ... }
つまり、
FilterExpressionでプレースホルダーを埋め込んだ条件式を与える- 実際の値を
ExpressionAttributeValuesで与える
と検索ができる、というだけの簡単な仕組みです。どのキーでも検索対象とできますが、文字通りのスキャンなので検索コストが跳ね上がる可能性があります。インデックスを追加して検索に使えるようにしてあげるというお馴染みの手法で改善を図れます。
query()で検索・その1
scan()のかわりにquery()を呼んでも検索ができます。ただし今度の検索条件にはプライマリキーの指定が必須となります(不自由な分だけ低コストです)。たとえばSQLで SELECT * FROM TABLENAME WHERE key = 'A' に相当する検索ならこうなります。
var param = {
TableName : "TABLENAME",
KeyConditionExpression : "#k = :val",
ExpressionAttributeValues : {":val" : "A"},
ExpressionAttributeNames : {"#k" : "key"}
};
dynamo.query(param, function(err, data) { ... }
KeyConditionExpressionでプレースホルダーを埋め込んだ条件式を与える- 実際の値を
ExpressionAttributeValuesで与える
- 検索するプライマリキー・セカンダリキー名に
keyやFILEといった予約語 を使っている場合はエラーになる
#から始まる適当な別名(上の例では#k)を付けて、その実際のキー名をExpressionAttributeNamesで与えることで回避できる
プライマリキーが条件に含まれていれば、セカンダリキーを追加で指定することもできます。
var param = {
TableName : "TABLENAME",
KeyConditionExpression : "#k = :val and key2 >= :val2",
ExpressionAttributeValues : {":val" : "A", ":val2" : "Q"},
ExpressionAttributeNames : {"#k" : "key"}
};
dynamo.query(param, function(err, data) { ... }
query()で検索・その2
query()はKeyConditionExpressionではなくKeyConditionという別の形のパラメーターも受け付けます。ただ、こちらは冗長で読みづらいだけでなく、ドキュメントに「古いやり方なのでもう使うな」とあるため使用は避けるべきでしょう*2。上と同じ検索を行うコードは次の通りです。
var param = {
TableName : "TABLENAME",
KeyConditions : {
key : {
ComparisonOperator : "EQ",
AttributeValueList : {S : "A" }
},
key2 : {
ComparisonOperator : "GE",
AttributeValueList : {S : "Q" }
}
}
};
get()で検索
get()はレコード1件だけを取得するためのメソッドです(内部的にはAWS.DynamoDB.getItem()を呼び出します)。つまり検索条件からレコードを特定できないといけないので、プライマリキーの指定は必須、テーブルにセカンダリキーが存在する場合はセカンダリキーの指定も必須になります(そうしないと"The provided key element does not match the schema"と言われてエラーになります)。パラメーターの形はだいぶ違いますがその分だけシンプルになります。
var param = {
TableName : "TABLENAME",
Key: {
key : "A",
key2: "Q"
}
};
dynamo.get(param, function(err, data) { ... }
- 大文字の
Keyは検索条件を示します。
- 小文字の
key, key2はテーブルのプライマリキー・セカンダリキーの名前です。
batchGet()で検索
内部的にはAWS.DynamoDB.batchGetItem()を呼び出します。検索レコード数が多いときなど、ページングを行うにはこちらのメソッドを使う必要があります。今回は省略します。
上述のAPI、つまりAWS.DynamoDBを直接呼び出すこともできます。全件検索はこうなります。
var AWS = require("aws-sdk");
var dynamo = new AWS.DynamoDB();
exports.handler = function(event, context) {
dynamo.scan({TableName : "TABLENAME"}, function(err, data) {
if (err) {
context.fail(err);
} else {
context.succeed(data);
}
});
};
2行目を除いてDocumentClientの例と全く同じです。ただし結果の形式が異なり、フィールドの型が明示的に指定されます。ドキュメントの中でも言及されている通り、数値(整数・実数)の区別があるため厳密ですが、状況によっては使いづらいかもしれません。
{
"Items": [
{
"key": {
"S": "A"
},
"key2": {
"S": "P"
},
"str": {
"S": "ap"
},
...
現時点でAPIのバージョンには2012-08-10版と2011-12-05版の2種類があり、どちらかを明示的に指定することもできますが、古い方をあえて指定するメリットはなさそうです。省略すれば新しい方になります。
var AWS = require("aws-sdk");
var dynamo= new AWS.DynamoDB({apiVersion: '2012-08-10'});
scan()で検索
FilterExpressionが使えます。
var param = {
TableName : "TABLENAME",
FilterExpression : "num = :val",
ExpressionAttributeValues : {":val" : {N : "10"}}
};
dynamo.scan(param, function(err, data) { ... }
ScanFilterも使えます。
var param = {
TableName : "TABLENAME",
ScanFilter : {
num : {
ComparisonOperator : "EQ",
AttributeValueList : [{N : "10"}]
}
}
};
dynamo.scan(param, function(err, data) { ... }
query()で検索
ドキュメントにはKeyConditionExpressionが使えると書いてあるのですが、エラーになってうまくいきませんでした。KeyConditionsなら動きます(ただしDocumentClient版とは微妙にパラメーターの形が違います。AttributeValueListには配列を渡さなければなりません)。
var param = {
TableName : "TABLENAME",
KeyConditions : {
'key' : {
ComparisonOperator : "EQ",
AttributeValueList : [{S : "A"}]
},
'key2' : {
ComparisonOperator : "GE",
AttributeValueList : [{S : "Q"}]
}
}
};
dynamo.query(param, function(err, data) { ... }
getItem()で検索
DocumentClientと同じ形で検索条件を渡せば同じ結果が返ってきます。
var param = {
TableName : "TABLENAME",
Key: {
key : {S : "A"},
key2: {S : "Q"}
}
};
dynamo.getItem(param, function(err, data) { ... }
dynamodb-docを使う
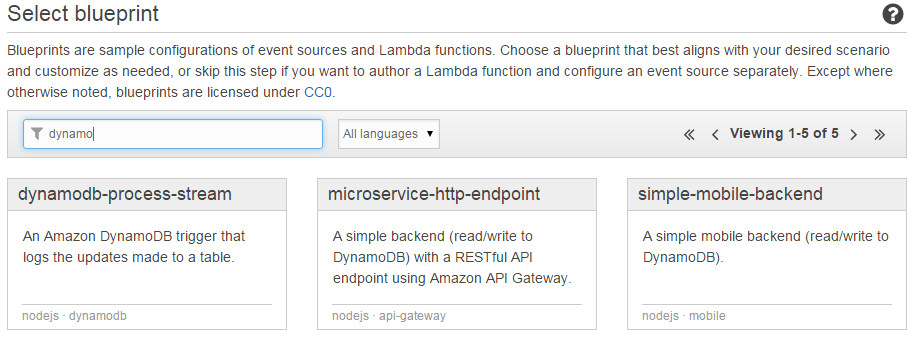
Lambdaのblueprintで"DynamoDB"が名前に付くものを探すといくつか候補が出てきますが、この中で使われているものです。
var doc = require('dynamodb-doc');
var dynamo = new doc.DynamoDB();
exports.handler = function(event, context) {
dynamo.scan({TableName : "TABLENAME"}, function(err, data) {
if (err) {
context.fail(err);
} else {
context.succeed(data);
}
});
};
dynamodb-document-js-sdk だと思われますが、こちらはNOTEに記載されている通り今後はメンテナンスされません。使わない方が無難だと思われます。
まとめ
DynamoDBのAPIはずいぶん長い間放っておかれていたように思っていたのですが、そのせいか古い情報がまだ数多く残っています。ドキュメントを熟読するのは大切だなあと思った一コマでした。